
About me
I am a graduated student in National Yang Ming Chiao Tung University,Taiwan. My thesis is "Model-Agnostic Training with Sample Selection for Fair and Robust Learning".
I am familiar with deep learning related technologies, including trustworthy AI and computer vision.
In addition, I am also interested and passionate in information technology, including database, cloud, software design and development.
Education
Sep 2021 - Jul 2023
National Yang Ming Chiao Tung University (NYCU)
Master's Degree, Institute Of Information Management

Sep 2017 - Jun 2021
National Taipei University (NTPU)
Bachelor's Degree, Statistics

Sep 2014 - Jun 2017
National Hsinchu Senior High School

Professional Skills
Subjects
- Deep Learning
- Trustworthy AI
- Computer Vision
- Optimization
- Data Mining
- Machine Learning
- Statistical Modeling
- Algorithm
- Cloud Computing
- Database
Skills
- Python, C, C++
- PyTorch, Tensorflow, Keras
- LINUX
- GIT, Bitbucket, Jira
- Airflow, MLflow
- AWS, Azure
- Google Cloud Platform
- BigQuery, GCS
- Composer, Pub/Sub
- Function, Scheduler
Language
- Chinese
- English (TOEIC 720)
AI/ML Related Course Record
Deep Learning
CM, NYCU (交大電信所)
Spring 2022, GRADE: A+
- Implement FNN gradient descent using only python numpy package.
- Establish CNN and ResNet to classify images by PyTorch.
- Establish Transformer to classify news documents by PyTorch, Top 2 accuracy in class .
- Implement VAE and GAN to create anime face by pyTorch.
- Build DQN and Actor-Critc RL model on Lunarlander using PyTorch.
Machine Learning
EE, NYCU (交大電子所) & MTK
Spring 2022, GRADE: A
- Train an image classification model on CIFAR-100 with limited size, 100MB.
- Build ResNet-50 and use SAM Optimizer (2021, Google).
- Achieve almost 83% accuracy.
- Final project is building road image segmentaion model on mediaTek chip.
- Using U-Net and post-training quantization to compress tflite model.
- Achieve 0.735 mIOU, Top 3 in class.
- Using Keras, scikit-learn build ml model such as random forest, xgboost, LSTM... to do sentiment analysis, time series prediction etc.
- Construct Hadoop & Pyspark to compute matrix factorization distributedly.
Work Experience
AI Engineer Intern
MediaTek Inc. (AIDE/AI Team)
Jan 2023 - Jun 2023
Hsinchu City, Taiwan
- Wafer parametric map anomaly auto recognition (Self-Supervised learning).
- Solve wafer map missing value issue by per-pixel mean, global mean method.
- Build wafer map anomaly pattern classifier by PyTorch Lightning and Hydra.
Data Engineer Intern
MediaTek Inc. (AIDE/DE Team)
Jun 2022 - Dec 2022
Hsinchu City, Taiwan
- Supporting AI project in data pipeline and ETL.
- Build statistics and completeness KPI of test item and die in CP、FT、SLT three test stage.
- Using Python Airflow and Big Query、 Google Cloud Storage to establish auto data schedulers.
- Construct loosely-coupled structure by pub/sub service on GCP.
AI/ML Related Competition
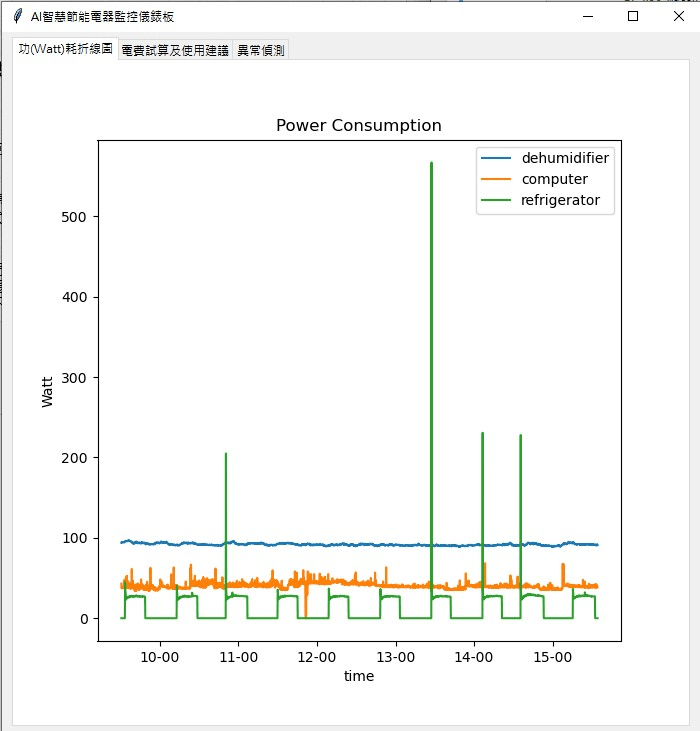
2022 TSMC x Microsoft Careerhack
TSMC & Microsoft
Jan 2022
Work: Energy-Efficient Dashboard
The IOT device connects to the home appliance, transmits the collected electricity consumption data to the azure IoT center, and uses python to capture the data in the blob storage to organize the data and present it on the smart dashboard, providing home appliance users with a clearer understanding of home appliances power consumption details and electricity bill trial calculation, so as to achieve smart power consumption and energy saving.

The 6th ETC Traffic Data Competition
MOTC, ROC
Aug 2020
Work: CATS - Clog AlerT System
After using a variety of models to build, the best prediction model for the backlog mileage is obtained, and the influence of different variables on the backlog mileage is explored. By exploring the importance of variables and building models, the possible back-blocking impacts after future national highway accidents can be dealt with more quantitatively and systematically.

2020 NTPU Stats Research Project Competition
NTPU Stats
Jun 2020
Work: P2P Default risk forecast
Using Logistic regression and random forest to construct a default prediction model of P2P online lending platform, the data is obtained from Lending Club, from 2016~2019.
Certifications
TOEIC
720
Apr 2018

Big Data Analyst and Machine Learning Engineer
(Industry Professional Assessment System, IPAS)
Nov 2021, Dec 2022


