
賴朝祥
我是一名熱情的軟體工程師。畢業於國立台灣科技大學電子所,研究方向為機器學習與電腦視覺,善常撰寫高效率的TensorFlow程式,近期熱衷於動作偵測辨識及定位、多物件偵測/追蹤。 常常閱讀CVPR研討會論文,學到了很多影像處理的相關知識,也對最近幾年非常熱門的深度學習有許多經驗,特別是訓練旋積神經網路的技巧。 碩士論文以深度學習為基礎,利用光達(Lidar)與影像(RGB)兩種資訊的結合,建構一個三維空間的多物件偵測旋積神經網路模型,並應用於汽車自動駕駛系統上。
Python、TensorFlow、Deep Learning、Machine Learning、Image Processing
軟體、演算法、影像處理工程師
學歷
國立臺灣科技大學, 電子工程所, 碩士學位, 2016 ~ 2018
- 於影像/視訊信號處理與機器學習實驗室研究AI深度學習,碩論題目為「利用三維重疊率損失函數以優化三維物件偵測網路及其在自駕車之應用」,利用光達(Lidar)與影像(RGB)兩種資訊的結合,使用TensorFlow建構三維空間的多物件偵測旋積神經網路模型。
- 參與工業技術研究院資通所計畫「影片標記註釋-應用於自動駕駛系統」,透過少許人力手動標記影片註釋與weekly supervised的方式蒐集並更新資料,結合物件偵測與追蹤,達到自主學習標記準確率極高的影片註釋。
- 參與工業技術研究院資通所計畫「碰撞偵測-應用於自動駕駛系統」,透過多種感測器判斷行進車道與預測前方車輛軌跡,實現車輛碰撞前警示。
國立臺灣海洋大學, 電機工程系, 學士學位, 2012 ~ 2016
- 專題實驗為「應用DS18B20在Arduino上控制理想溫度之溫度感測計」,運用DS18B20溫度感測器將類比訊號(溫度)轉換成數位訊號傳給Arduino(微控制器),透過撰寫程式及電路設計,適當調節風扇轉速及顯示當下溫度。
專業技能
研究領域
Deep Learning
Machine Learning
Image Processing
程式語言
Python, C
Matlab
擅長工具
TensorFlow
Caffe
OpenCV

多益 845

中高級初試 通過
重要經歷
持續精進碩論
比起二維物件偵測網路能達到超過90%準確率,三維物件偵測網路(約75%準確率)還有很大的進步空間。目前最主要的目標為提升執行速度與精準度,像是用更精準的編碼方式法表達三維空間中的特徵、改變網路架構更能對抗over-fitting的問題、改變感測器資訊融和的方法等。

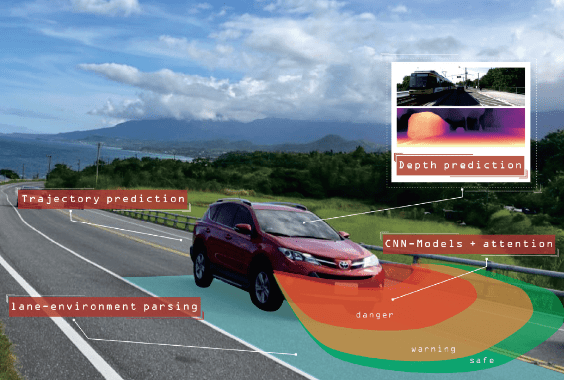
工研院計畫 (Pre-crash Detection)
參與工業技術研究院資通所計畫「碰撞偵測-應用於自動駕駛系統」,只透過單一影像(無雙鏡頭與深度感測器)辨識行進車道與預測前方車輛軌跡,實現車輛碰撞前警示。其中,利用Faster RCNN進行物件偵測、Mask RCNN進行車道辨識、LSTM預測前方車輛軌跡、Self-supervised估計深度,並結合以上特徵進行決策,判斷即將碰撞的可能性。
工研院計畫 (Video Annotation Tool)
參與工業技術研究院資通所計畫「影片標記註釋-應用於自動駕駛系統」,只透過少許人力手動標記影片註釋與Weekly-supervised的方式蒐集並更新資料,結合物件偵測(Faster RCNN)與追蹤(SiameseFC tracker),達到自主學習標記準確率極高的影片註釋。另外,值得一提的是人力標記的部分,我們寫了一個群眾外包(crowd-sourcing)的APP減低標記時的成本。


校外課程 (IEEE International Elite School)
除了校內的課程,我很高興能上 IEEE International Elite School 開的 “Machine Learning for Big Visual Data” 課程,由美國華盛頓大學電機系黃正能教授教授電腦分析和學習影像的技術,並且介紹目前國際權威的設計原理和方法,深入探討視覺數據的監督式與非監督式學習、從類神經網路、深度學習到影像物件追蹤的應用等。讓我對這個領域有更多不同面向的了解,也學習到很多校內課堂上沒有的資訊和知識。
線上課程 (e.g. Stanford CS231n Lecture)
有著探索新技術及解決問題的熱枕,利用網路資源自己精進,像是Stanford University的CS231n:Convolutional Neural Networks for Visual Recognition和CS224d:Natural Language Processing with deep Learning、University of Toronto的CSC321:Intro to Neural Networks and Machine Learning等,除了新技術的學習,也培養自己設計上的靈敏度。

研究作品
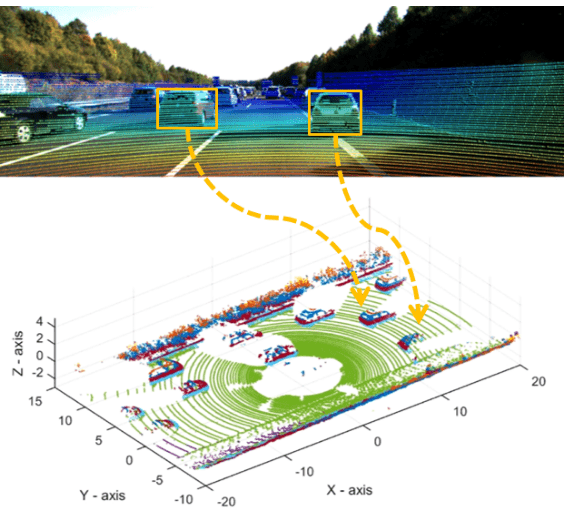
三維物件偵測 (碩論)
二維空間的資訊(RGB影像)不足以準確描述道路駕駛環境,結合三維資訊(Lidar光達),利用Lidar與RGB兩種資訊的結合,互補不同sensor的優缺點,實現三維空間的物件偵測模型。



- 左:道路駕駛環境示意圖
- 中:光達擷取影像
- 右:二維/三維物件偵測結果
- 左:車載攝影機
- 右:光達俯視圖
多物件追蹤
- 追蹤成功:保持相同ID編號(顏色)
- 追蹤失敗:被認定維其他ID,甚至都沒偵測到物件
