Ming-Chieh Chen
I graduated from the Department of Information Engineering, Tamkung University, and my research interests are artificial intelligence, data analysis, web backend, and related works in computer science. The programming languages that I am good at are Python and C, and I use them for data analysis and web crawling.
Experience
April 2019 ~ Now
Freelancer (Python developer)
November 2018 ~ March 2019
Army Reserve Command, Private, four months of compulsory service
September 2015 ~ June 2018
Tamkang University, Department of Information Engineering, Bachelor's degree
January 2014 ~ February 2015
Formosa University of Science and Technology, Department of Electrical Engineering, undergraduate (transfer)
September 2010 ~ June 2013
Taichung Municipal Taichung Industrial High School, Department of Automatic Control, vocational high school
Skills
Programming
Python, C, HTML/CSS, JavaScript, Google App Script, Batch
Tool
Git/Git flow, Visual Studio Code, Jupyter NotebookLicenses & certifications
Pearson Test of English (PTE) 49
TOEIC 735
Project
Enterprise Monitoring Software System Construction
Through Pyqt5 (C++ Qt), I develop desktop application software to monitor office equipment. The monitoring part directly calls the windows built-in API to maximize performance (compared to using the package, greatly reducing the system load), combined with QThread ( Qt built-in multi-threading), real-time warning notifications, and through Requests Library, which can be connected to related API ( AWS cloud services, Line, Discord, telegram....) to carry out messages Notification function
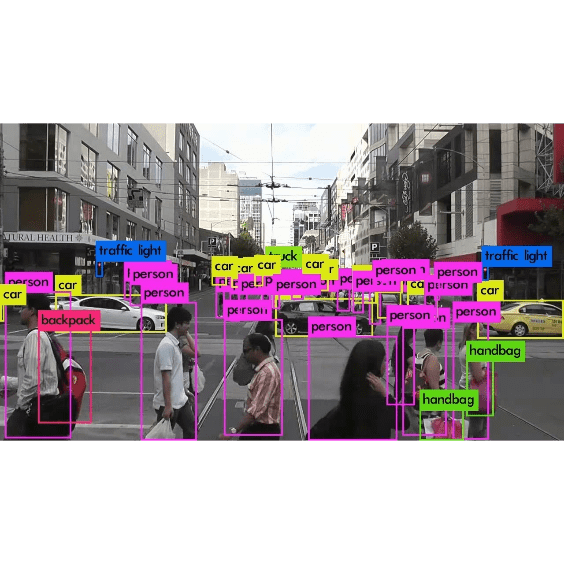
Deep Learning Object Recognition and Tracking
This is a government's case. The yolov3 model of the tensorflow-gpu keras version is created to identify objects of a specific category, and vgg-16 is used to calculate the similarity between objects in different frames to achieve real-time tracking. I will use vgg16 instead of opencv to track mainly because of the image itself has too few frames per second, and the object distance between frames has changed too much. Later, I switched to vgg16 and found that the accuracy is still OK, but the demand for GPU hardware increase a lot
Machine Learning Chemical Tank Prediction Alert System
Under limited hardware and software constraints, by building a multiple linear regression prediction system, time-consuming neural network model building is saved, while maintaining a high degree of prediction accuracy, and the raw data is normalized through python , At the same time, it connects to the docker Hana database of the factory, and backfills the forecast data to the database in real time, and then analyzes and predicts the data. When the forecast result exceeds the set upper and lower limits, the system will send an alarm.

Internet of Things Voice Recognition Search Engine


Customized Chatbot API
Using the TF-IDF algorithm, Jieba (NLTK in English) is used to preprocess the word-Segmentation answer set for keywords, and then through the recommendation algorithm designed by yourself, the ranking list is sorted according to the similarity to find the most suitable answer, and through Flask designs the web backend API, and returns the results to the web front-end

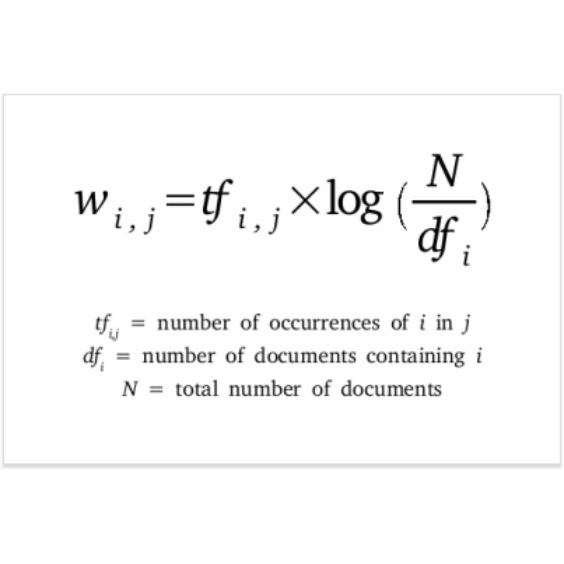
Asynchronous Multi-Thread/Processing Customized Web Crawler
Use asyncio (asynchronous) and multi-Thread/processing to make a crawler program, first make a large number of requests through asyncio, and set the request waiting time, and then use multiprocessing to find out datas in the .html file through bs4 and regular expression, and achieve the maximum efficiency of crawler execution time.
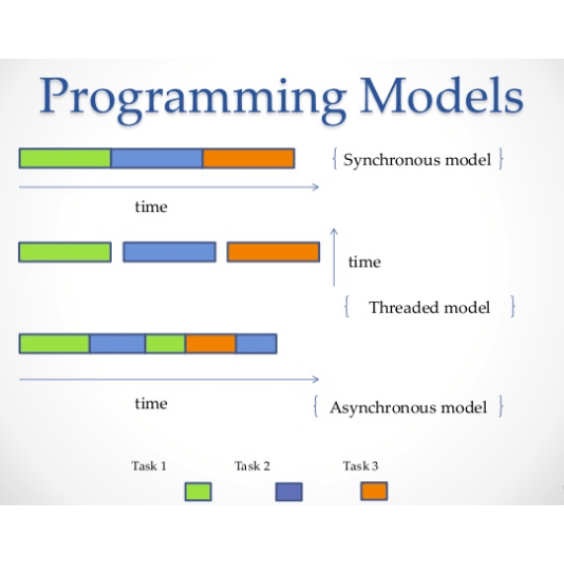
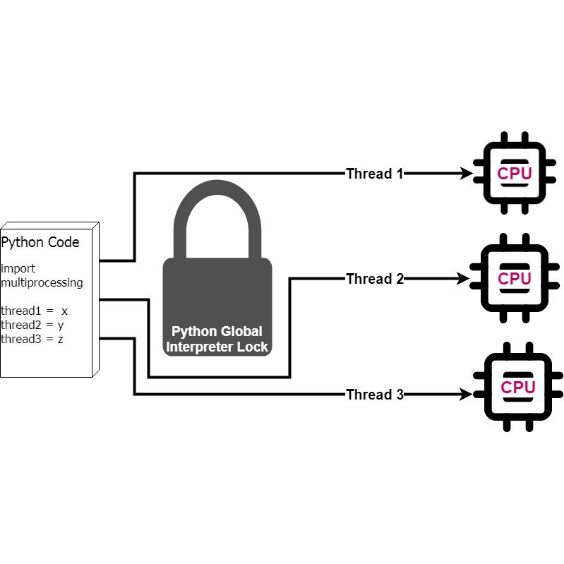
Simple Crawler Public Works


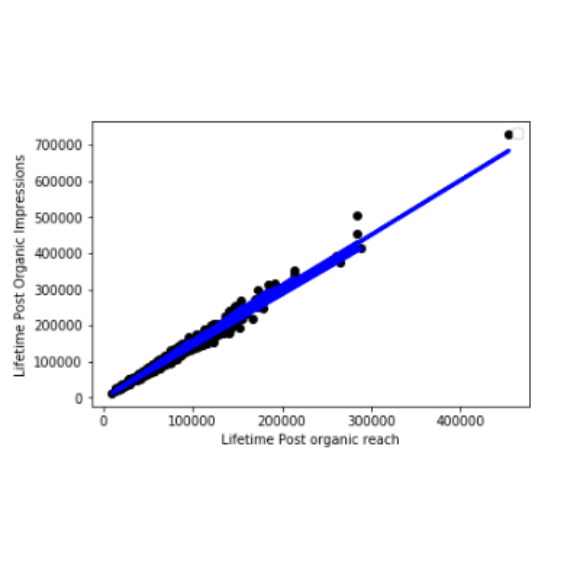
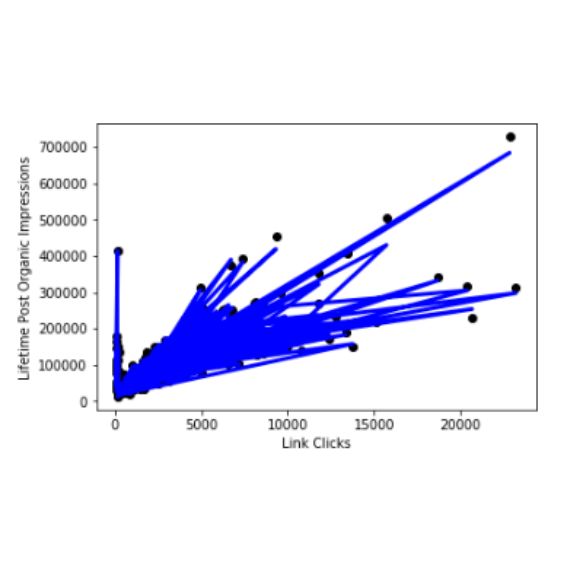
Facebook Fan Page Clicked Rate Prediction
This is a public project.
(1) By using Lifetime Post organic reach and Link Clicks to predict the professional Lifetime Post Organic Impressions of this fan?
(2) I used Multiple Linear Regression to build the model, where r_squared is as high as 0.98389, and the correlation between the data and the model is very high
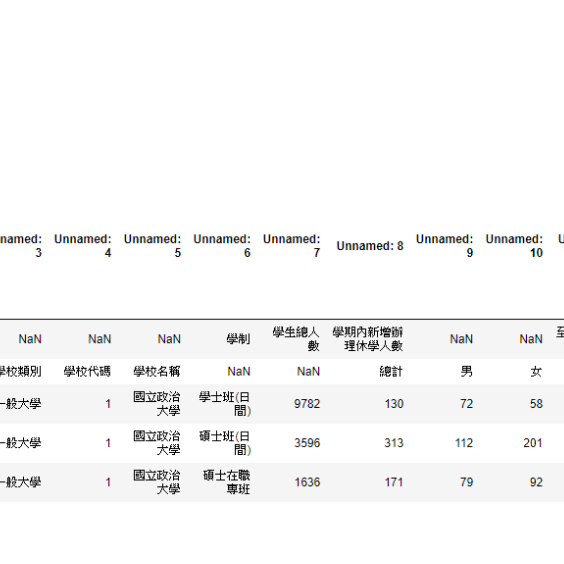
Prediction System for Dismissal of Colleges and Universities
This is a public project.
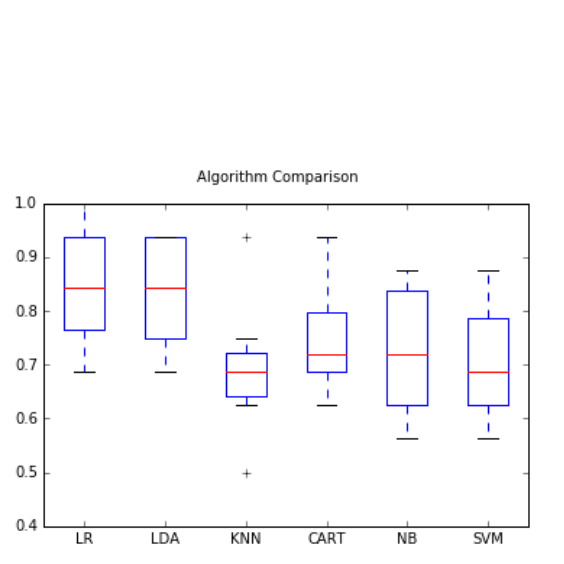
(1) Use the total number of students and the number of new suspensions during the semester to predict whether the suspension rate of this school after the end of the semester will exceed the total average suspension rate of all schools in Taiwan. The accuracy is tested Up to 80%
(2) It is possible to judge whether the school is a public general university or a public university of science and technology based on
1. the total number of students
2. the number of new suspensions during the semester
3. the total number of suspensions at the end of the semester.