
何長億 Chang-Yi Ho
因為興趣讓我踏入資料庫領域。
樂於技術分享,讓彼此夥伴都成長,是我最享受的事。
擁有3年資料庫開發經驗,5年的資料庫管理經驗。
負責資料庫管理、DataWarehouse建置、指導開發人員撰寫良好的SQL語法。
良善的調校,成功幫助公司減少硬體成本支出。
目前進修機器學習,希望可以有效幫助公司得到更好的市場分析。
樂於技術分享,讓彼此夥伴都成長,是我最享受的事。
擁有3年資料庫開發經驗,5年的資料庫管理經驗。
負責資料庫管理、DataWarehouse建置、指導開發人員撰寫良好的SQL語法。
良善的調校,成功幫助公司減少硬體成本支出。
目前進修機器學習,希望可以有效幫助公司得到更好的市場分析。
🏫南 臺 科 技 大 學 - 資訊管理學系 2009/09~2013/06( 畢 業 )
🧑💻資料庫管理師
📌Taichung, Taiwan 📞 +886 979177887
✉️ [email protected]
工作經歷
尊博科技股份有限公司, 資料庫管理師, Oct 2019 ~ 在職
- 系統架構優化
- 資料庫效能與稽核資料進行監控(Python / influxdb / Grafana) 搭配監控發送告警( Telegram / Slack / Line)
- 資料庫備份檔每日災難還原測試
- 與各單位進行溝通並效能調校
- DataWareHouse建置並提供BI 環境
- 宣導如何正確使用索引
信業國際有限公司, 資料庫管理師, Oct 2018 ~ Oct 2019
- 產品需求開發
- 系統架構優化
- 資料庫 Alwayson 建置維護
- 資料庫問題解決方案分享
- 資料庫效能監控(Python / influxdb / Grafana)
- 資料庫備份檔每日災難還原測試
- 歷史資料保存規劃與建置
向上國際科技股份有限公司, 資料庫工程師, Sep 2014 ~ Sep 2018
- 老子有錢 / GoldCity / 新百老匯/ 新至尊 等產品需求開發
- 產品資料庫系統邏輯架構轉移
- 平台轉移(Local > GCP)
- 自動化版本部屬建置(SVN > Jenkins >Octopus)
- 資料庫效能監控(Telegraf /Influxdb / Grafana)
- 資料庫備份檔每日災難還原測試
- 歷史資料保存規劃與建置
- 協助營運單位與大數據單位的報表資料提供
專業技能
Database
- MSSQL:
- Build and Maintain DataBase
- Tunning Code
- Build and Maintain Alwayson
- Planning Backup And Restore Test
- Sharing Problem Solved
- Clickhouse:
- Build Replication and Sharding
Monitor
- Python:
- Data collection(MSSQL information Data)
- Telegraf:
- Data collection(Disk IOPS/CPU / Memory / Network)
- influxdb:
- Store Monitoring information Data
- Set Retention Policies
- Grafana:
- Store Produce execution count / 10s
- Store Produce Read Disk Size(KB) / 10s
- Store Produce execution time / 10s
- Database Latency (Write & Read) / 10s
- Disk IOPS / 10s
- CPU / Memory / Network
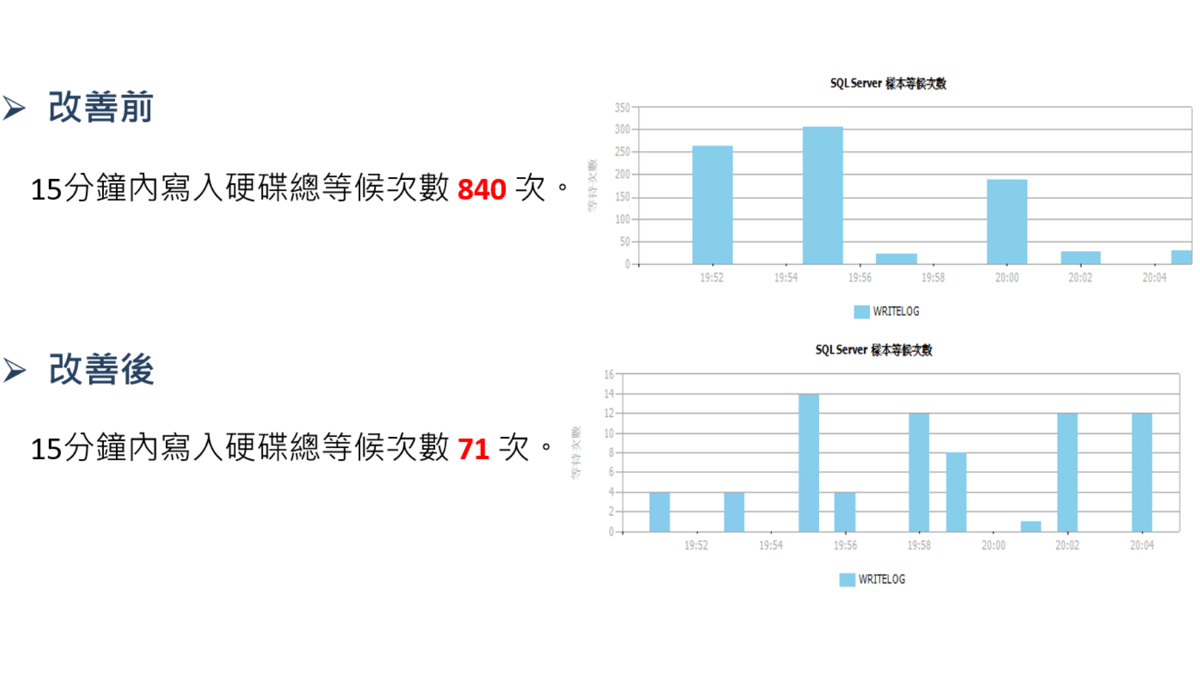
資料庫問題事件處理(一)
- 問題:
- GCP 壓力測試無法達到預期壓力值(預期6000人同時spin)。
- GCP 壓力測試無法達到預期壓力值(預期6000人同時spin)。
- 原因:
- 資料庫處理作業等候次數過高,導致效能不佳
- 改善方式一:
- 將 Transaction Log (LDF) 與 Database File (MDF/NDF)實體的磁碟分開存放。
- 在完整模式下,LDF 可以放在磁碟效能較好的硬碟。
- 改善方式二:
- 當所有的Database 都需要使用TempDB 時,只能循序等待,所以會產生競爭等待使用 TempDB 的問題。
- 增加檔案可以分散I/O,I/O產生時會分散至多個檔案,效能好過於一個檔案單獨承擔I/O 。
- 改善方式三:
- 調整資料庫檔案自動成長量大小,並監控紀錄每小時與每日的資料庫磁碟空間成長量。
- 進行往後檔案初始大小配置的調整,達到的利用有效的磁碟空間,並確保資料庫的效能穩定。
資料庫問題事件處理(二)
- 問題:
- primary DB 的.mdf 在合理的大小情況下
.ldf size 異常的大 導致 FullBackup , diff Backup 變大(有壓縮過)
- 差異備份大小幾乎等於完整備份大小,導致磁碟空間剩 9G
- primary DB 的.mdf 在合理的大小情況下
.ldf size 異常的大 導致 FullBackup , diff Backup 變大(有壓縮過)
- 差異備份大小幾乎等於完整備份大小,導致磁碟空間剩 9G
- 原因:
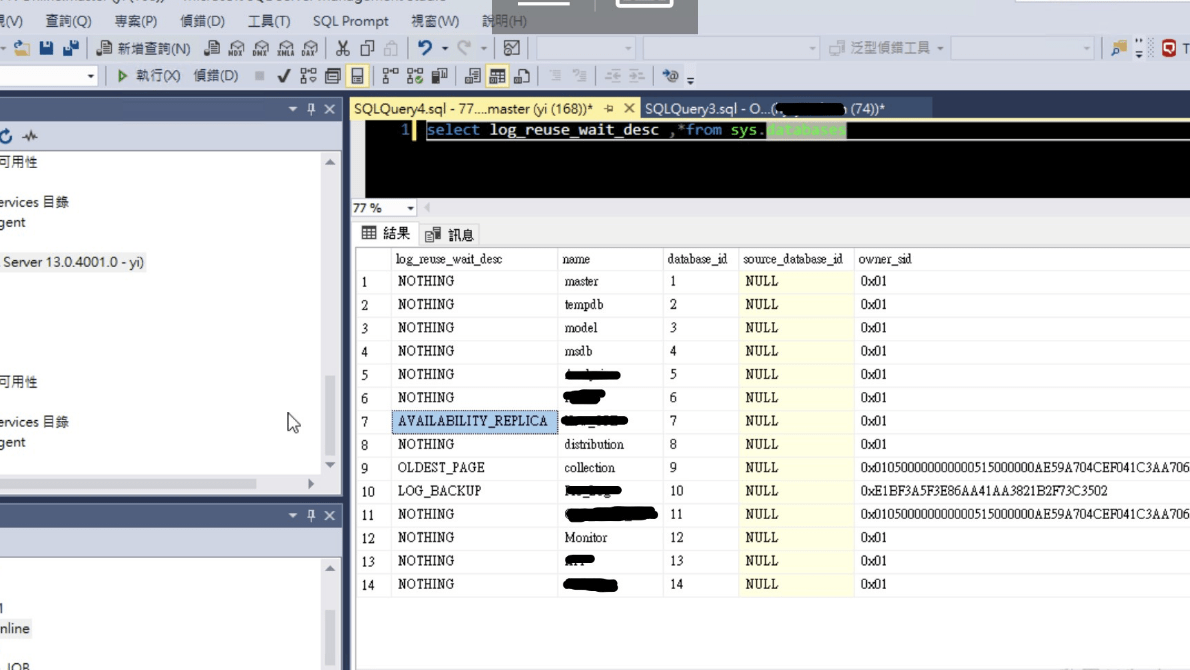
- 在 sys.databases
發現該DB的 log_reuse_wait_desc:
AVAILABILITY_REPLICA
於是查看Alwayson的儀錶板
發現另一個secondary 的該DB 未同步
- 當一個DB 同步發生異常時
主要DB會因為次要的關係
導致無法截斷log
- 改善方式:
- 將該 secondary 複本先從AG Group移除
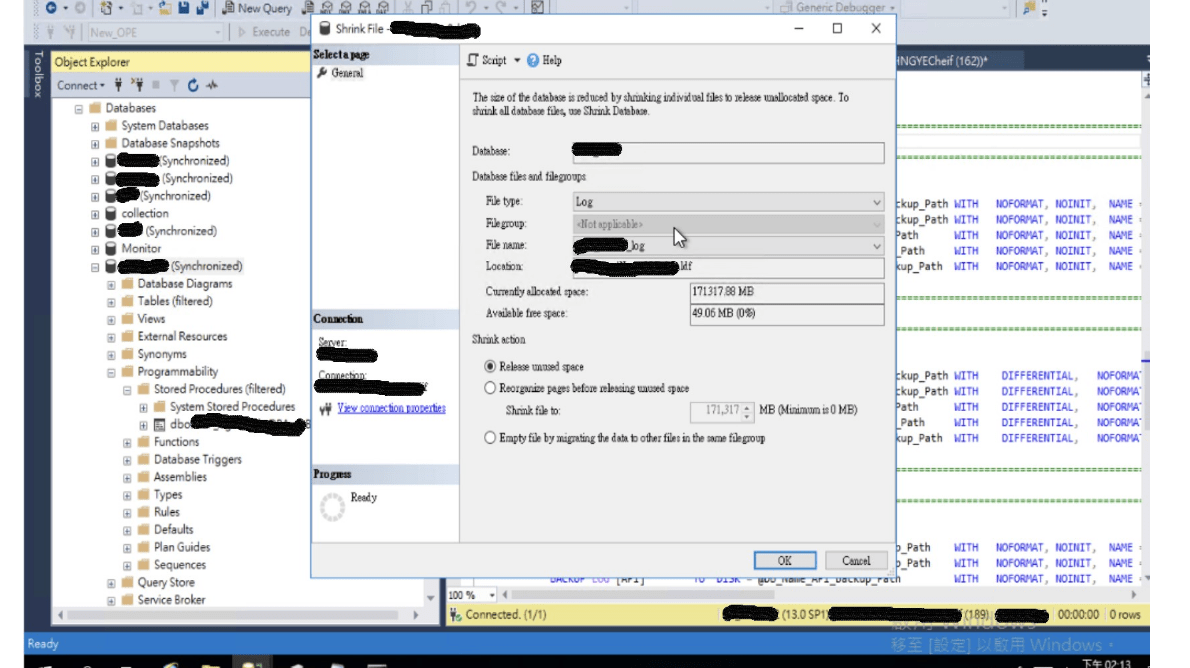
- 回到 primary 看該 DB 的 log file available free space 回來 99%
- 進行針對該DB 進行 DBCC SHRINKFILE secondary 處理
- 將 secondary 的複本的所有DB 做 RECOVERY
- 將 secondary 的所有DB DROP
- 回到 primary 將 secondary 加回去到AG Group 加入成功
檢查點1
已確定該 DB 的 log file available free space = 0 % 所以無法DBCC SHRINKFILE
檢查點2
發現該DB的 log_reuse_wait_desc: AVAILABILITY_REPLICA
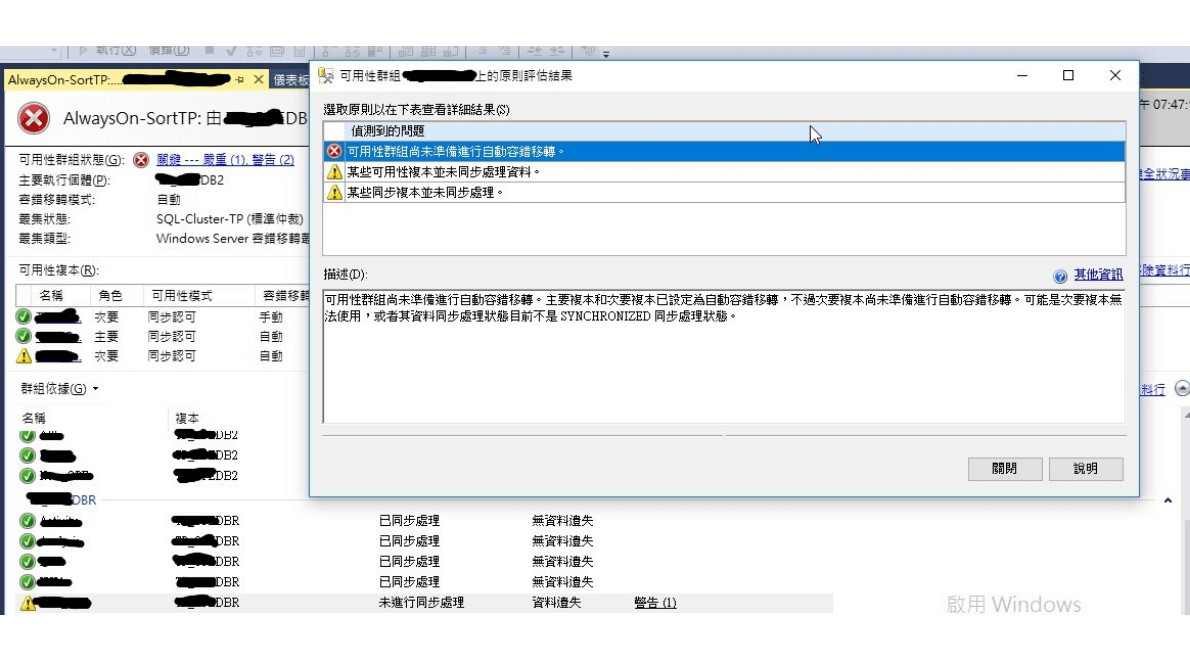
檢查點3
查看Alwayson的儀錶板 發現另一個secondary 的該DB 未同步
