
技能
機器學習與建模
• 算法: Tree-based models; Logistic Regression; XGBoost; KNN; SVM; Credit Score Card; ARIMA; Prophet; Clustering; Apriori; Bayesian analysis; Statistical Modelling
• 統計模擬: System Dynamics; Agent-based Modelling; Monte Carlo
程式語言/軟體
• Programming skills: R; Python (pandas, NumPy, Scikit-learn, statsmodel, apyori, fbprophet, pytorch)
• Software: SPSS; Anylogic; SAS; Matlab; MS Excel
• Web: Dash, Flask, HTML
工作技能
• Working Skills: Interdisciplinary Communication; Verbal/Writing; Public Speaking; Presentation
• Git; MySQL; PostgreSQL; Docker; Ubuntu; Airflow
專案

英國國民健保署: 自動救護服務分析
方法:根據業務需求設計自動特徵篩選模型,並以Python進行模型應用與特徵篩選工具之設計。 成果:改變與加速組織中統計分析流程,也為未來建模者提供建模的特徵篩選框架。本計畫亦用此工具,分析2019年影響英格蘭中南部救護服務的變因,如何與何時影響,並提供政策建議。研究內容已發表為學位論文。
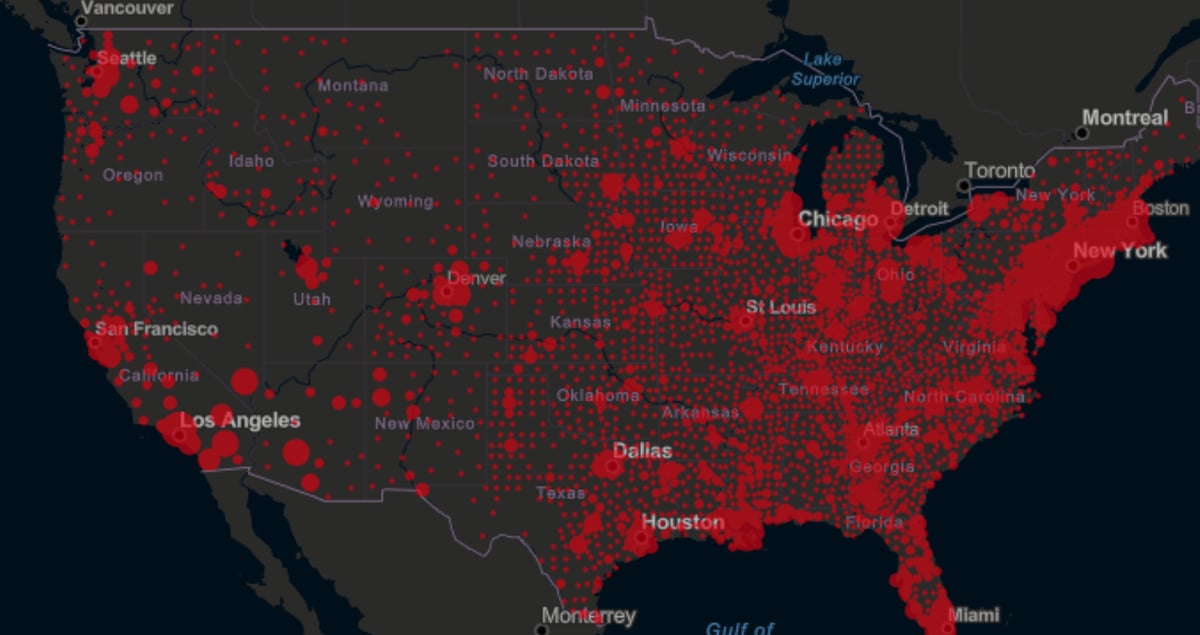
美國Covid-19風險評分
方法:獲取美國網民對疫情關鍵字的搜尋數據、醫療資源分布、外加空氣汙染指標 (分別反映大眾對疫情的關心,與地區受疫情干擾程度)。使用機器學習風險計分模型檢驗變數影響力;據此建立即時風險預測模型。 成果:所使用的變量,幾乎全數都具有反映疫情的能力,且數據可透過公開管道或爬蟲即時獲取,有利於做出即時風險預測和監控。

中國股市與總體經濟的連動
方法:分析反映投資、生產、消費、貨幣政策與房地產相關經濟變數和上證指數的滯後關係,並了解如何變化。以關聯規則方法分析,用關聯規則數量反映滯後關係。 成果:探討中國股市與經濟間滯後關係的演化。發掘了影響股市不同程度波動的重要因素。
Github: https://github.com/DarrenTsungjenWu/Chinese-Stock-market-and-Macroeconomics
工作經歷
Welhunt Material Enterprise
Data Scientist|Dec. 2020 - present
• 研究經濟、天氣、船運及國際原物料市場,找尋並爬取資料建置Data Centre。
• 將原物料市場的領域知識,用於feature engineering以自製特徵,優化並使模型多樣化。
• 機器學習建模,掌握衍生性金融商品走勢以利交易人員進行投資與避險。
• 歸結國際市場主要買家的購買行為,使用時間序列與機器學習方法視覺化掌握交易規則,並呈現出不同國家決策時的節點
• 設計Dashboard,設計前端與連接後端資料庫,以呈現研究發現與觀測指標,監測/預判主要購買國的交易活動
South Central Ambulance NHS Foundation Trust, UK
數據分析師|Jun. 2020 - Oct. 2020 (英格蘭南安普頓)
【專案: Developed an automated performance analysis framework for the 999 emergency response services】
• 與supervisors 和 project sponsors 定期溝通需求與進度,確保最終產品交付的形式與品質
• 運用機器學習為基礎的特徵篩選算法──Sparse Logistic Regression,篩選並解釋造成不良救護服務的因素
• 對 555,000+ 筆緊急救護服務數據 (即999 Incident Data) 進行數據預處理(pandas),並應用特徵篩選算法分析跨週、跨月與跨時樣本數據,總結出不同時間段救護服務的表現差異
• 使用Python (Scikit-learn) 將特徵篩選器產品化,自動化project sponsors傳統分析流程,即時地辨識重要因素
量化投資社群
• 發起交易系統開發專案,打造具解讀市場情緒 + 綜合預測未來股市變化的交易預測系統
• 組建最小專案戰鬥團隊 (工程師、分析師與投資研究員,橫跨台灣與美國),統合跨領域知識,協調專案進展所需資源
• 監管建模流程與prototype品質,確定產品概念與構圖
• 預處理與測試數據,反覆驗證與強化Forecasting/機器學習模型
南京大學計算機科學中心
• 瀏覽數據挖掘與股市研究文獻,提出以數據挖掘為基礎的研究主題──中國股市是否是宏觀經濟的晴雨表?
• 預處理上證指數與8個涵蓋生產、消費、貨幣與房價的經濟指標 (2000-2017年);以視覺化處理,查看波動之關聯
• 使用Apriori演算法(Python的apyori frameworks),分析上證指數與經濟指標的滯後關係,以此回答經濟理論中的重要命題:中國股市是不是有效市場,以及在17年期間如何演變
學歷
University of Southampton, UK,2019 年 9 月 - 2020 年 10 月
• (MSc) Business Analytics & Management Sciences
• 2.1 Academic Excellence Scholarship/5000 pounds
• Dissertation: What factors impact poor 999 services, and how? An empirical study of machine-learning-based feature selection on big data from South Central Ambulances Services NHS Foundation Trust
南京大學,2019 年 3 月 - 2019 年 7 月
• 2019春季交流計畫:政府管理學院
• 眾創空間3D列印空間志工解說員、值班管理員
• 相關課程:公共管理研究方法、數據科學、大數據分析基礎
國立政治大學,2014 年 9 月 - 2019 年 6 月
• 經濟學系/中國文學系雙主修 學士
• 研究興趣: 總體經濟、公共經濟 (公部門經濟研究)、貨幣銀行學理論、聲韻/漢語語言
更多作品

統計建模/分析:公共經濟

統計建模/分析:開源健康資料
病人健康如何影響罹患心臟病的機率?本作品旨在展示不同的特徵組合,如何影響模型的解釋力。同時設計/改善Matlab程式碼進行分析,並分別對感興趣的特徵繪出變數─機率擬合圖。

Forecasting
本作品為技術報告,主要涉及模型訓練、統計判斷以及模型比對之流程。測試Exponential Smoothing模型,並與ARIMA模型進行比較。
