
廖彥勛(Ivan Liao)
Data Analyst/ AI Engineer/Machine Learning Engineer
核心技術: 開發AI模型、資料庫語法、數據分析專案、自動化流程及API
專攻程式: Python、SQL
成功大學財金所(GPA: 3.9/4.3),大學就讀應用數學系,具備跨領域能力
Taipei City, Taiwan [email protected] 0972-185978 TOEIC: 840
程式能力
Python SQL Deep Learning Docker Machine Learning
Linux Git Mongo Elastic Search Google Ads
專長
AI人工智慧
NLP
- 使用語言: Python
- 模型架構: Pytorch、Tensorflow
- 模型應用: BERT、ALBERT、DistilBERT、XLNet
- 實作領域: 預測商品分類、營業秘密要件預測、文本相似度計算
Deep Learning
- 使用語言: Python
- 模型架構: Pytorch、Tensorflow
- 模型應用: CNN、VGG16、ENN、CoANet
- 實作領域: 預測商品分類、英特爾影像辨識
Machine Learning
- 使用語言: Python
- 模型架構: sklearn
- 模型應用: KNN、XGBoost RandomForest、Regression
- 實作領域: 預測公司破產、超額認購對於公司過度投資的影響、Titanic 存活分析預測
數據分析
Python
- Process Automation: 開發自動化流程專案,以定時執行數據分析任務
- Data Analysis: 利用pyodbc從SQL撈取數據,進行資料預處理,並藉由商業邏輯開發演算法
- API Deployment: 利用flask建構API,並使用docker部署上線,以協助前端進行UI設計
- Web Crawler: 使用request、beautifulsoup爬取官網文字內容、司法院網站的判決書
SQL
- Stored Procedure: 開發SQL自動化流程,以定時執行資料更新以及任務
- Query: 熟悉SQL語法,有效提升邏輯運算及撈取效能
Google Ads
- 廣告類型: Shopping campaign, Search campaign
- Google ads API: 透過使用Big Query語法呼叫API,取得線上SKU的表現數據,協助專案開發
Other Database
- 資料庫: Elastic Search, Mongo
- 應用: 透過將數據匯入以上資料庫,以提升Query效能,進而優化API反應時間
Linux
- 熟悉基本操作語法,並建立Python Virtualenv,避免開發階段影響線上其他程式
- 具備git操作經驗
Personality
- 具備團隊合作以及(跨組)溝通能力
- 個性堅毅認真,熱心助人,經公司同仁投票獲選為勞方代表
工作經歷
資料分析師(ML)
台灣新蛋股份有限公司 • 八月 2021 - 六月 2022
- 建立深度學習模型(ALBERT、XLNet、DistilBERT),預測商品分類,提升搜尋引擎的品質。過程訓練近184萬筆的商品文字資訊,且可預測類別高達480類,最終準確度來到87%以上,且修正近30萬筆錯置的商品
- 和前端進行跨組合作,以開發搜尋關鍵字績效API及邏輯,提供使用者有效率的查詢系統
- 開發自動化流程的分析專案(Python、SQL),並利用Airflow進行排程上線
- 開發google ads相關專案,為專案設計排除重複SKU的機制,並提供其他關鍵字專案近90萬筆的數據源,以提升廣告投放效益
【預測商品分類模型】
專案目的: 建立商品預測模型,以修正錯誤分類的商品,優化平台搜尋結果
專案流程: 撈取數據 → 模型訓練 → 開發及部署API → 開發自動化流程及上線
- 撈取數據: 透過SQL撈取商品的文字資訊,總共取得184萬筆數據進來訓練
- 模型訓練: 分別訓練三大模型ALBERT、XLNet、DistilBERT,最終Top5準確度皆超過87%
- 開發及部署API:利用flask架構設計出API,讓使用者透過輸入商品編號或是商品資訊取得模型預測結果
- 開發自動化流程及上線 : 透過取得Market部門的待測商品名單,並呼叫三大模型API取得預測類別。經過整合及備份模型預測的邏輯,將最終結果回傳到指定Table並更新任務狀態。 專案結果: 每天執行一次流程,累積修正了近三十萬筆錯誤分類的商品
【搜尋關鍵字績效API】
專案目的: 提供使用者關鍵字對應前五名熱門商品的資訊,以便賣家擬定行銷策略
專案流程: 數據準備及運算 → 匯入數據庫 → 開發及部署API
- 數據準備及運算: 透過有效率的整合及運算多張SQL Table數據,並開發成SP
- 匯入數據庫: 經過測試Mongo及Elastic Search效能,最後選擇匯入後者因為該資料庫對於搜尋結果的檢索能力是較強的
- 開發及部署API :利用flask架構設計API,將使用者輸入的keyword及條件(時間、地區、顯示筆數、頁數等)轉換成ES的Query語法,整理成Json格式並回傳查詢結果
專案結果: 在數據為百萬級別及大量文字的情況下,API反應時間從6秒優化到2秒,滿足前端UI開發需求以及使用者高效能的查詢

行政人員
聖喬科技股份有限公司 • 六月 2019 - 六月 2020
該新創公司致力於研發智能投資領域,利用AI技術進行投資分析,滿足金融構資產配置的需求。
- 負責撰寫客戶提案書及財務分析,為公司計算出合理估值
- 擔任公司聯絡窗口,包含協調公司網頁的設計、公司UI系統及創投基金的會談,展現溝通能力及團隊合作,協助公司技術及業務的推展

學歷

國立成功大學
財務金融研究所
2018 - 2020

國立嘉義大學
應用數學系
2014 - 2018
專案

工作專案-預測商品分類
專案目的:
建立商品預測模型,修正錯誤分類的商品
專案流程:
撈取數據 → 模型訓練 → 開發及部署API → 開發自動化流程及上線
專案成果:
利用超過一百萬筆數據訓練三大模型(ALBERT、XLNet、ALBERT),可預測類別為480類,最終Top5準確度皆超過87%以上,修正了近三十萬筆錯誤分類的商品

工作專案-搜尋關鍵字績效API
專案目的:
提供使用者關鍵字對應前五名熱門商品的資訊
專案流程:
數據準備及運算 → 匯入數據庫(Mongo、Elastic Search) → 開發及部署API
專案成果:
將運算結果匯入ES,最終在大量文字及一百萬筆級別的情況下,API反應時間從6秒優化到2秒,滿足前端UI開發需求以及使用者高效能的查詢

工作專案-Google Ads專案開發
專案目的:
取得google ads線上數據
專案流程:
研究google ads API → 開發自動化流程及上線
專案成果:
設計排除重複SKU機制,並從購物廣告的關鍵字取得九十萬筆的數據,為其他廣告專案注入數據源

技術協助-營業秘密要件預測
專案目的:
目的為辨識公司技術或其他資料是否為營業秘密
專案流程:
數據準備 → 數據清洗 → 模型訓練及預測
專案成果:
最後利用預訓練模型ALBERT進行分類訓練,輸出準確度將近0.88

專案目的:
建立影像辨識模型以分辨該圖片屬於何種分類
專案流程:
影像預處理 → 模型訓練 → 模型評估
專案成果:
成功訓練CNN(2層卷積層、2層池化層+NN)、VGG16(取前13層輸出特徵+NN)、ENN(取前13層輸出特徵+1層卷積層+1層池化層+NN),準確度分別為0.777、0.873、0.886
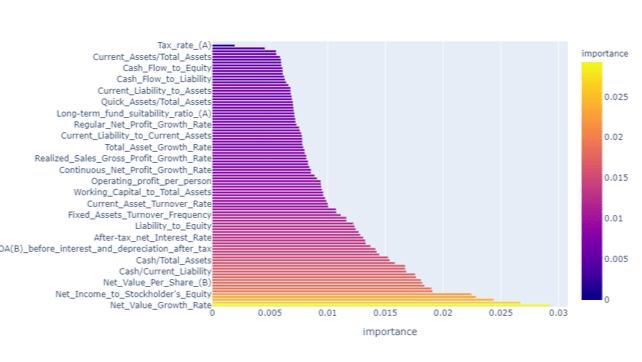
專案目的:
建立機器學習模型,利用財務數據預測公司是否會破產
專案流程:
數據清洗→ 特徵工程及EDA → 模型訓練 → 模型評估
專案成果:
透過特徵選擇將95個篩選到25個,最終成功訓練出預測模型KNN、Random Forest及XGBoost,準確度分別為0.950、0.977、XGBoost: 0.978
