I acquired the Master Degree of Computer Science at National Central University in 2019. I major in researching Deep Learning(Data-Driven models) in the period of master course. My thesis is about clickstream behavioral modeling. We build a service for collecting user online behavior. I also research the stock price prediction. In the period of acquiring Master degree, I have experience on processing Million-scale data and speeding up the procedure from 3 days to 3 hours and building a service from zero.
I joined Pinkoi on December 2019 and had been laid off by Pinkoi since April 2020 because the COVID-19 let Pinkoi need to downsize. In the 4 months at Pinkoi, I refactored the code repository for speed up data pipeline development , which make data team care less when building new data pipeline and fetch data more efficiency. I re-launched the projects about search-bar autocomplete system which data pipeline was down for several months and brand-suggestion system which was down for more than 3 years. I re-work the search-bar autocomplete system in the latest code style and keep the performance as before. The brand-suggestion system was finished in latest code style, too. However, I tune the performance of the brands' coverage from ~1500 up to ~11000 brands(~15000 brands in total).
Collegiate Programming Examination(CPE) - Professional(Ranking:176 / 2044(8.6%))[Proficient with fundamental algorithms and data structures, and possessing good programming ability.]
I acquired the Master Degree of Computer Science at Nation Central University on July 2019. For my thesis, I built a system include front-end and back-end to serve user with visualize personal data and collect user behavior as background target. Finally, we analyzed the user behavior in the collected data. Before I start to involve to my thesis, from March to June 2018, I participated in the data competition held by Trend Micro. We won the 7th place in the 487 team competition. In July 2018, I applied for an intern job in Industrial Technology Research Institute(ITRI) with score of the competition. I worked on Business AI model development in Big Data Center for two months.
I joined Pinkoi.com on December 2019 and I have been laid off by Pinkoi since April 2020 because the COVID-19 let Pinkoi.com need to downsize. In the 4 months at Pinkoi, I refactored the code repository for speed up data pipeline development , which make data team care less when building new data pipeline and fetch data more efficiency. I re-launched the projects about search-bar autocomplete system which data pipeline was down for several months and brand-suggestion system which was down for more than 3 years. I re-work the search-bar autocomplete system in the latest code style and keep the performance as before. The brand-suggestion system was finished in latest code style, too. However, I tune the performance of the brands' coverage from ~1500 up to ~11000 brands(~15000 brands in total).
Experience
Pinkoi.com,Data Engineer,Dec 2019 – Apr 2020, 4 mos
Routine works are maintaining ETL pipeline, responding the data request from other teams(BI, UX ... etc.)
Key Achievement:
Refactor Code repository and fix up several issues: Make teammate develop more efficiency than before about 10% fast and more readable than before about 50%.
Search-bar autocomplete system: refactored in new data pipeline and make it renew everyday while keeping the system performance.
Search-bar brand-suggestion system: redesign it by using association rules for cleaning the user behavior and merging the brand list to maximized the recall. Finally, tuned the performance of the brands' coverage from ~1500 up to ~11000 brands.
National Central University,Mar 2017 – Jul 2019,2 yrs 5 mos
Researching Assistant — Mar 2017 – Jul 2019,Data Analytics Research Team
Server Management, Homepage design and development, and Database Management
Teaching Assistant — Feb 2018 – Jan 2019
Statistical Learning, Sep 2018 - Jan 2019 Computer Organization, Feb 2018 - Jun 2018
Industrial Technology Research Institute(ITRI),Intern,Jul 2018 – Aug 2018,2 mos
Business Application Analysis Technology Department of Huge Data Center
Works Applications Co., Ltd.,,Intern,Jul 2017,1 mo
Design and Develop ERP system for global coffee shop.
National Changhua University of Education,Feb 2015 – Jun 2017,2 yrs 5 mos
Teaching Assistant — Feb 2015 - Jun 2017
Object-Oriented-Programming, Feb 2015 - Jun 2017 Advanced Programming Design, Feb 2017 - Jun 2017
Bachelor Project — Jul 2015 - Jun 2016
"A new sub-system of enrollment in college management system", Jul 2015 - Jun 2016 "Data Migration for sub-system of club management in college management system",Jul 2015 - Feb 2016
Education
National Central University, Department of Computer Science & Information Engineering, Data Analytics Research Team- Master,Sep 2017 - Jul 2019
National Changhua University of Education, Department of Computer Science & Information Engineering — Bachelor,Sep 2013 - Jan 2017
Publications
Ting-Rui Chen, Hung-Hsuan Chen. Extended Clickstream: an analysis of the missing user behaviors in the Clickstream, 2019.
Nowadays, people often use clickstream to represent the behavior of online users. However, we found that clickstream only represents part of users' browsing behaviors. For instance, clickstream does not include tab switching and browser window switching. We collect these kinds of behaviors and named as "extended clickstream". This thesis builds a service to capture both of clickstream and extended clickstream, also provides an analysis of the differences between above. We use a Multi-Task learning model with GRU components to perform multi-objective predictions of "what kind of website the user will go next time" and "how long the interval of clicks will be" for the time series of clickstreams and extended clickstreams. Our experimental results show that combining clickstream and extended clickstream can improve the prediction performance. In addition, this article finds that the clickstream will record unintended clicks due to the operation mechanism of certain websites. Moreover, we can differentiate the single user from several devices by combining the clickstream and extended clickstream.
This paper introduces a dataset containing the logs
of online users’ long-term cross-website visits. Such
type of open dataset is rarely-seen because collecting
the logs of users’ long-term cross-website visits is
difficult. As a result, opening such a dataset may help
the researchers conduct advanced researches, such as
online user behavior analysis, user demographical
information analysis, recommender systems and online
advertising system development, etc. We report the
following items in this paper. First, we explain the data
collecting process. Second, we show the basic statistics
of this dataset. Third, we discuss the concerns to
release the complete dataset. Specifically, we discuss
the trade-offs between “openness” and “privacy” and
our current compromising sharing policy. Fourth, we
introduce experiments based on this dataset. Finally,
we introduce our current plan for expanding this dataset.
Keywords: online log, open data, user behavior.
Cheng-You Lien, Guo-Jhen Bai, Ting-Rui Chen, Hung-Hsuan Chen. Predicting User’s Online Shopping Tendency During Shopping Holidays. TAAI '17 Conference on Technologies and Applications of Artificial Intelligence, 2017.
The number of sales during the shopping holidays continues growing in recent years. Thus, many E-Commerce (EC) websites spend much money and effort for marketing before these shopping holidays. However, in this study we found that only part of the Internet users indeed visited the EC-websites more often than usual during the shopping holidays. Thus the increase of the sales probably comes from few individuals. Additionally, we found that users’ tendency to visit the EC websites during the shopping holiday is predictable based on simple supervised classifiers. Thus, an EC website runner can identify the potential visitors and non-visitors beforehand and apply different marketing strategy to different users.
Reference
[1]
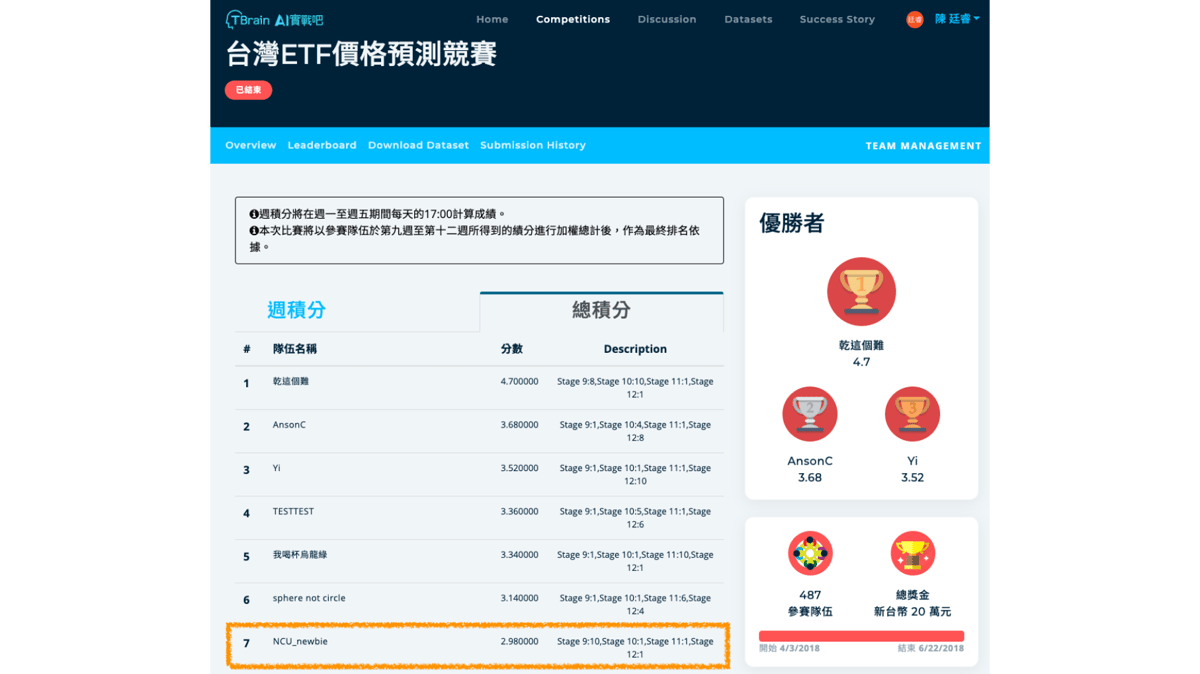
T-Brain Machine Learning Competition 2 Taiwan ETF Price Prediction Competition 7th Place (Team name: NCU_newbie) We took the first place in the first week of the game period. Analyzing the stock price trend in the game period, we found that stock price trend is similar as historical data in the first week, however, the Taiwan stock price trend in the next three weeks goes with global economic news. Therefore, our model cannot well predict the trend. Finally, we got overall 7th place in this competition. Our models are the deep learning models. Each model gets a prediction then ensemble by a simple machine learning model as a final prediction. Our method can learned the relation from the large-scale stock price historical data, but cannot learned relation from news. As a result, we cannot well predict the trend affect by news.
[2]
I managed the progress of the team and provide my knowledge of stock market to team members. I build base learner for prediction and the ensemble learner. In the second week of game period, we could not well predict the trend and we had no idea on parsing news to features. I suggested our team members to try everything. We set the goal to learn experience and knowledge.
PDF FILE INDEX: Japanese => p. 9
【Chinese】【2020.07.03 更新】
陳廷睿 Ting-Rui(Ray) Chen
2019年7月自國立中央大學資訊工程研究所畢業取得碩士學位,在學期間主要著重學習 Deep Learning(Data-Driven models)相關技術,著重的應用有二:股市預測、使用者行為分析預測。碩士論文主要研究透過點擊流分析使用者瀏覽網路行為,我們建置了一個服務蒐集使用者的行為,並且提出擴充的資料蒐集方式以提升模型的預測性能。
Collegiate Programming Examination(CPE) - Professional(Ranking:176 / 2044(8.6%))[Proficient with fundamental algorithms and data structures, and possessing good programming ability.]
Routine works are maintaining ETL pipeline, responding the data request from other teams(BI, UX ... etc.)
Key Achievement:
Refactor Code repository and fix up several issues: Make teammate develop more efficiency than before about 10% fast and more readable than before about 50%.
Search-bar autocomplete system: refactored in new data pipeline and make it renew everyday while keeping the system performance.
Search-bar brand-suggestion system: redesign it by using association rules for cleaning the user behavior and merging the brand list to maximized the recall. Finally, tuned the performance of the brands' coverage from ~1500 up to ~11000 brands.
Cheng-You Lien, Guo-Jhen Bai, Ting-Rui Chen, Hung-Hsuan Chen. Predicting User’s Online Shopping Tendency During Shopping Holidays. TAAI '17 Conference on Technologies and Applications of Artificial Intelligence, 2017.
The number of sales during the shopping holidays continues growing in recent years. Thus, many E-Commerce (EC) websites spend much money and effort for marketing before these shopping holidays. However, in this study we found that only part of the Internet users indeed visited the EC-websites more often than usual during the shopping holidays. Thus the increase of the sales probably comes from few individuals. Additionally, we found that users’ tendency to visit the EC websites during the shopping holiday is predictable based on simple supervised classifiers. Thus, an EC website runner can identify the potential visitors and non-visitors beforehand and apply different marketing strategy to different users.
Collegiate Programming Examination(CPE) - Professional(Ranking:176 / 2044(8.6%))[Proficient with fundamental algorithms and data structures, and possessing good programming ability.] ;
Routine works are maintaining ETL pipeline, responding the data request from other teams(BI, UX ... etc.)
Key Achievement:
Refactor Code repository and fix up several issues: Make teammate develop more efficiency than before about 10% fast and more readable than before about 50%.
Search-bar autocomplete system: refactored in new data pipeline and make it renew everyday while keeping the system performance.
Search-bar brand-suggestion system: redesign it by using association rules for cleaning the user behavior and merging the brand list to maximized the recall. Finally, tuned the performance of the brands' coverage from ~1500 up to ~11000 brands.
Ting-Rui Chen, Hung-Hsuan Chen. Extended Clickstream: an analysis of the missing user behaviors in the Clickstream, 2019.
Nowadays, people often use clickstream to represent the behavior of online users. However, we found that clickstream only represents part of users' browsing behaviors. For instance, clickstream does not include tab switching and browser window switching. We collect these kinds of behaviors and named as "extended clickstream". This thesis builds a service to capture both of clickstream and extended clickstream, also provides an analysis of the differences between above. We use a Multi-Task learning model with GRU components to perform multi-objective predictions of "what kind of website the user will go next time" and "how long the interval of clicks will be" for the time series of clickstreams and extended clickstreams. Our experimental results show that combining clickstream and extended clickstream can improve the prediction performance. In addition, this article finds that the clickstream will record unintended clicks due to the operation mechanism of certain websites. Moreover, we can differentiate the single user from several devices by combining the clickstream and extended clickstream.
This paper introduces a dataset containing the logs
of online users’ long-term cross-website visits. Such
type of open dataset is rarely-seen because collecting
the logs of users’ long-term cross-website visits is
difficult. As a result, opening such a dataset may help
the researchers conduct advanced researches, such as
online user behavior analysis, user demographical
information analysis, recommender systems and online
advertising system development, etc. We report the
following items in this paper. First, we explain the data
collecting process. Second, we show the basic statistics
of this dataset. Third, we discuss the concerns to
release the complete dataset. Specifically, we discuss
the trade-offs between “openness” and “privacy” and
our current compromising sharing policy. Fourth, we
introduce experiments based on this dataset. Finally,
we introduce our current plan for expanding this dataset.
Keywords: online log, open data, user behavior.
Cheng-You Lien, Guo-Jhen Bai, Ting-Rui Chen, Hung-Hsuan Chen. Predicting User’s Online Shopping Tendency During Shopping Holidays. TAAI '17 Conference on Technologies and Applications of Artificial Intelligence, 2017.
The number of sales during the shopping holidays continues growing in recent years. Thus, many E-Commerce (EC) websites spend much money and effort for marketing before these shopping holidays. However, in this study we found that only part of the Internet users indeed visited the EC-websites more often than usual during the shopping holidays. Thus the increase of the sales probably comes from few individuals. Additionally, we found that users’ tendency to visit the EC websites during the shopping holiday is predictable based on simple supervised classifiers. Thus, an EC website runner can identify the potential visitors and non-visitors beforehand and apply different marketing strategy to different users.
参照
[1]
T-Brain Machine Learning Competition 2 Taiwan ETF Price Prediction Competition 7th Place (Team name: NCU_newbie)
We took the first place in the first week of the game period. Analyzing the stock price trend in the game period, we found that stock price trend is similar as historical data in the first week, however, the Taiwan stock price trend in the next three weeks goes with global economic news. Therefore, our model cannot well predict the trend. Finally, we got overall 7th place in this competition. Our models are the deep learning models. Each model gets a prediction then ensemble by a simple machine learning model as a final prediction. Our method can learned the relation from the large-scale stock price historical data, but cannot learned relation from news. As a result, we cannot well predict the trend affect by news.
[2]
I managed the progress of the team and provide my knowledge of stock market to team members. I build base learner for prediction and the ensemble learner. In the second week of game period, we could not well predict the trend and we had no idea on parsing news to features. I suggested our team members to try everything. We set the goal to learn experience and knowledge.