- Jobs
 ResumeCreate your job-winning resume using our free resume builder.
ResumeCreate your job-winning resume using our free resume builder. PortfolioShowcase your skills and projects with a professional portfolio.ResumeCreate your job-winning resume using our free resume builder.Resume BuilderMake a resume for free.Resume TemplatesAccess our extensive library of professional & ready-to-use templates.Resume ExamplesGet inspired by real resume examples to create your own.Occupation GuideAccess resume writing guides tailored for different professions.Resume HelpGet expert advice on all things resume from our team of recruitment specialists.
PortfolioShowcase your skills and projects with a professional portfolio.ResumeCreate your job-winning resume using our free resume builder.Resume BuilderMake a resume for free.Resume TemplatesAccess our extensive library of professional & ready-to-use templates.Resume ExamplesGet inspired by real resume examples to create your own.Occupation GuideAccess resume writing guides tailored for different professions.Resume HelpGet expert advice on all things resume from our team of recruitment specialists.- ResourcesSuccess StoriesBusiness ExcellenceAbout CakeResumeFeatured Reads
- Hire
- Download our App



MR.中鑒者-多重部落格搜尋、業配文鑑定網站

MR.中鑒者-多重部落格搜尋、業配文鑑定網站
Senior Frontend Engineer
・
Taipei City, Taiwan
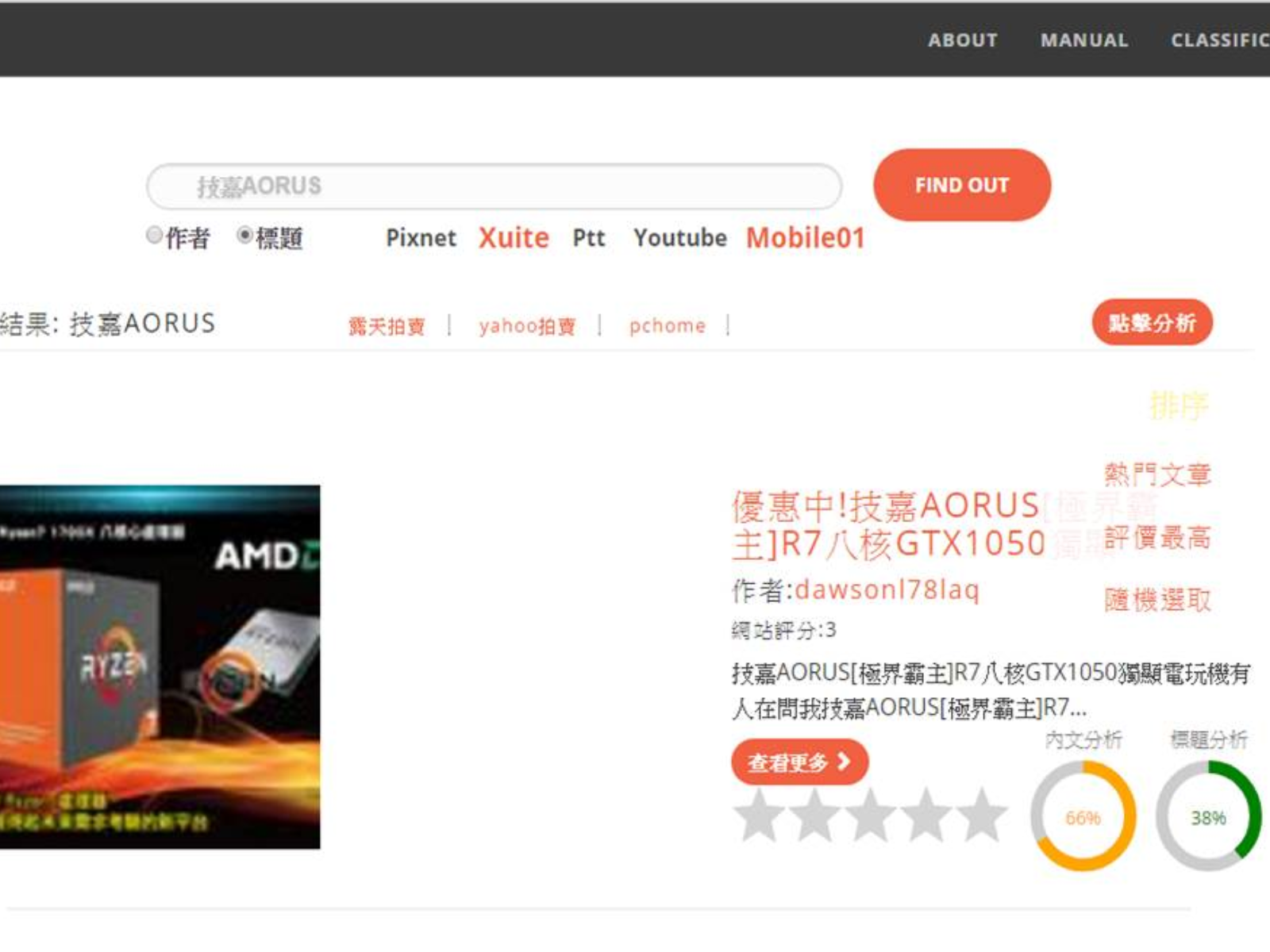
自學 Python ,使用 requests, BeautifulSoup 進行爬蟲,爬取各大部落客網站,以及 Youtube 搜尋頁面,在使用者提出關鍵字時,即時進行爬取,且對部落格文章,透過 jieba 進行初步簡單的 NLP 分析,將自訂的業配詞彙做出比對,以判斷是否像是業配文。
個人評價:僅做出網頁功能雛形,沒有考慮許多正式上線時會出現的狀況,工作量回頭看來非常淺顯,起因於成員間專案經驗欠缺、程式熟悉度不足,導致工作分配不均,隨意提個改善點:專案使用前後端分離的網頁架構會更好,除了爬蟲將後端 API 也一併完成讓前端 AJAX 取用為佳,不僅增加使用者體驗同時資料夾架構也比較完善。
4人專案 與一位夥伴負責完成爬蟲工作。
github: https://github.com/j551234/blog
Please login to comment.