
- Jobs
 ResumeCreate your job-winning resume using our free resume builder.
ResumeCreate your job-winning resume using our free resume builder. PortfolioShowcase your skills and projects with a professional portfolio.ResumeCreate your job-winning resume using our free resume builder.Resume BuilderMake a resume for free.Resume TemplatesAccess our extensive library of professional & ready-to-use templates.Resume ExamplesGet inspired by real resume examples to create your own.Occupation GuideAccess resume writing guides tailored for different professions.Resume HelpGet expert advice on all things resume from our team of recruitment specialists.
PortfolioShowcase your skills and projects with a professional portfolio.ResumeCreate your job-winning resume using our free resume builder.Resume BuilderMake a resume for free.Resume TemplatesAccess our extensive library of professional & ready-to-use templates.Resume ExamplesGet inspired by real resume examples to create your own.Occupation GuideAccess resume writing guides tailored for different professions.Resume HelpGet expert advice on all things resume from our team of recruitment specialists.- ResourcesSuccess StoriesBusiness ExcellenceAbout CakeResumeFeatured Reads
- Hire
- Download our App



About
Top Searches
Recommended Articles
Resume Examples & Writing Guide
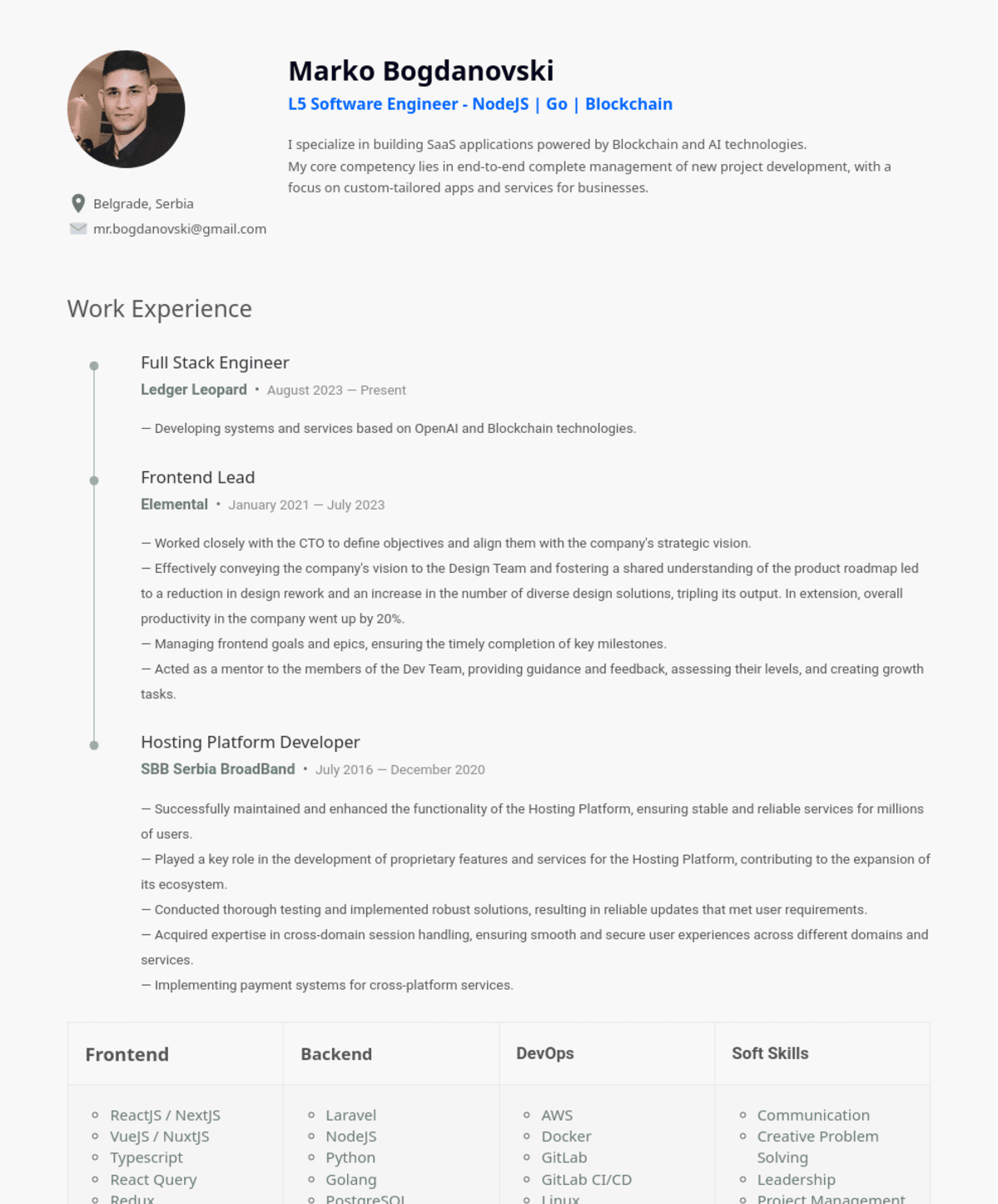




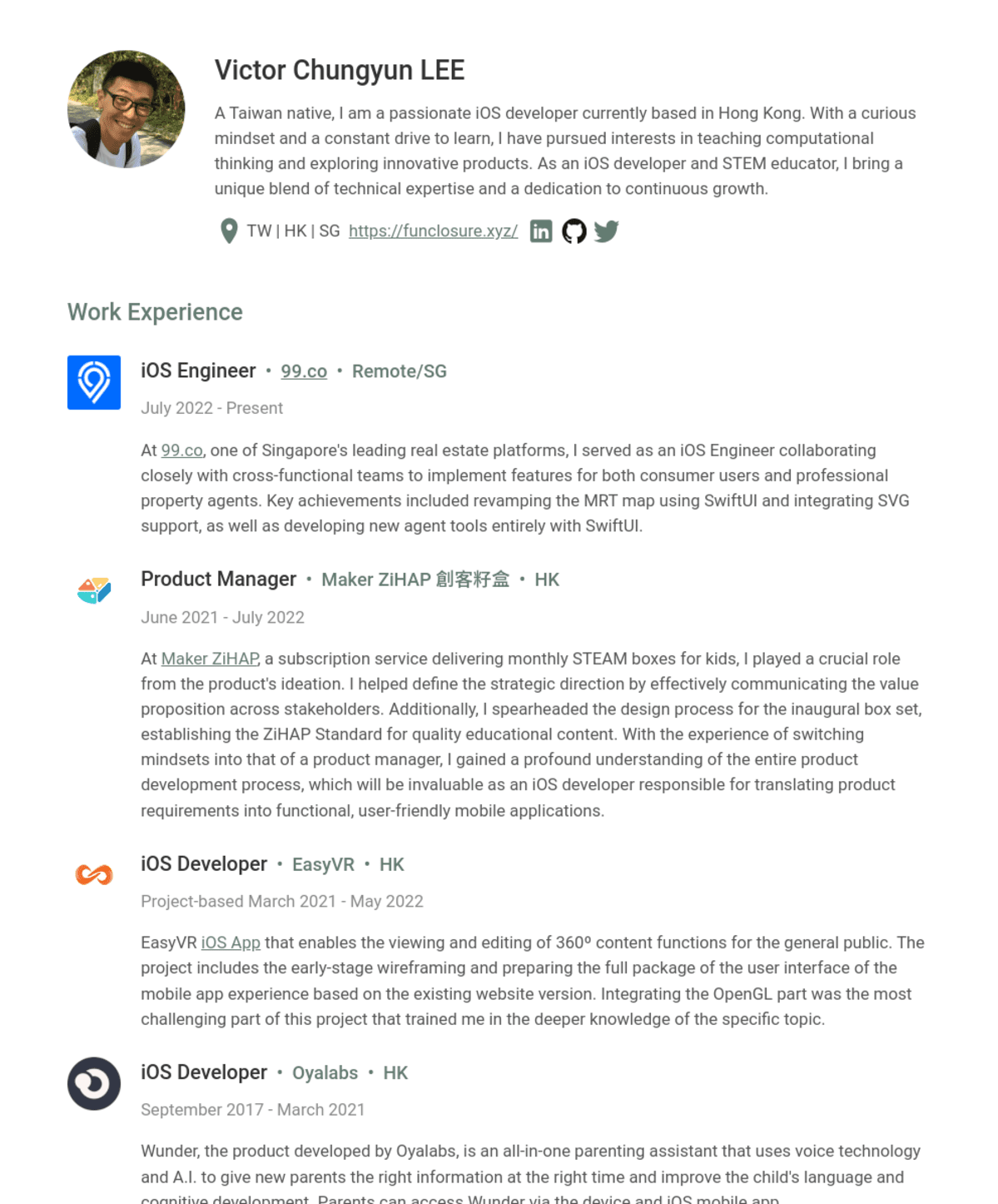
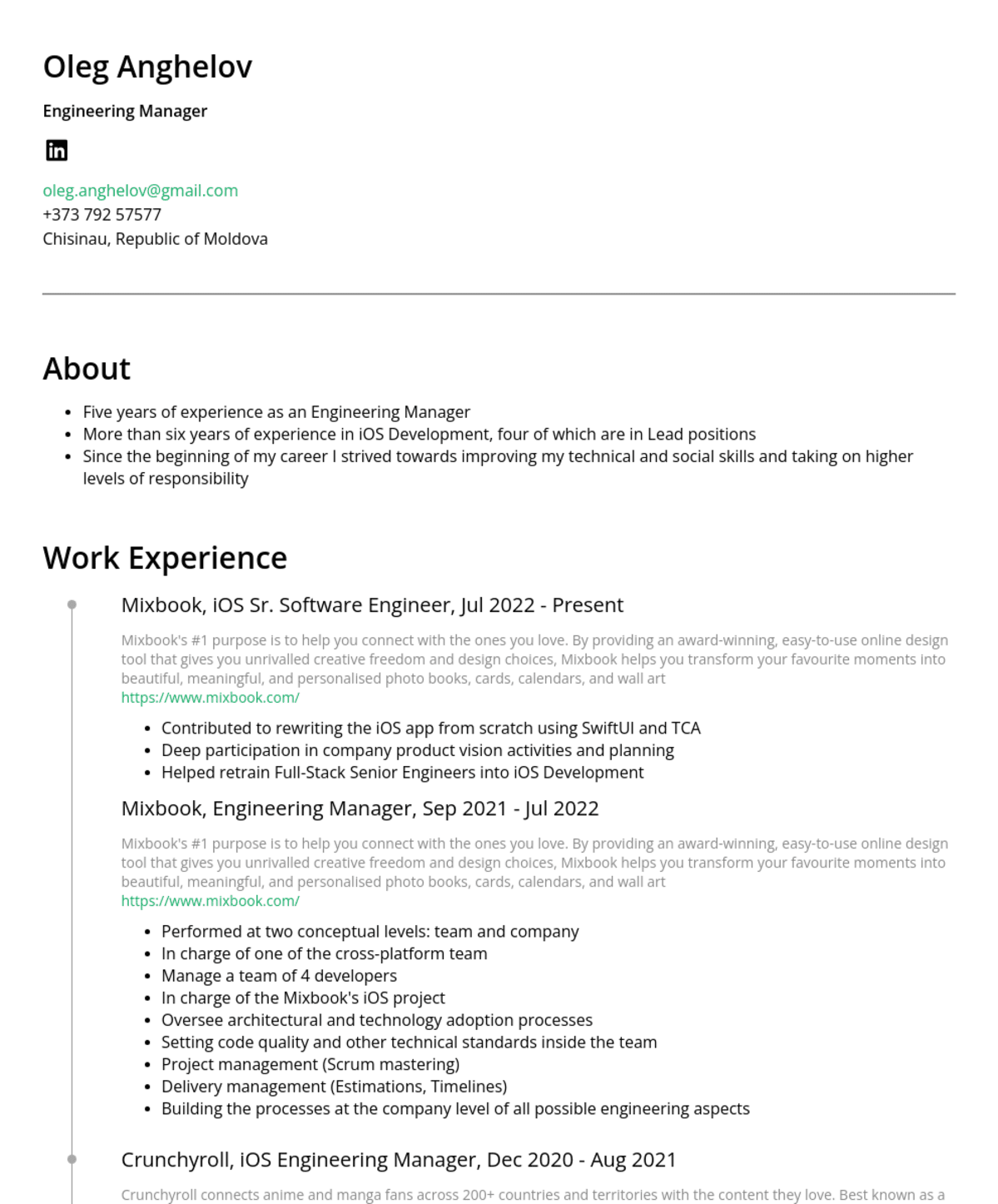




Resume
Profile